Rhizome is a very exciting technology as part of the Serval project. It allows to share data if there is a space-time path between two nodes, even if there is no space path at a given time.
I have read this documentation about the protocol, and I have some ideas to improve it I would like to discuss. Please tell me everywhere I say something incorrect or totally wrong, it would help a lot.
The concept is great and the current working version is very impressive. But in this document I will focus only on the drawbacks and limitations.
The protocol makes difficult the expiration of old data (on MeshMS).
There are two problems:
Imagine you send 5 big messages (voice mail). You receive acks for 1, 3, 4 and 5, but not for 2. In that case, stream_offset can be set only to the offset of message 2, and 3, 4 and 5 cannot be dropped (and will continue to be shared with other peers). This is what the document says page 5:
The stream_offset value cannot advance based on the reply of a single message recipient, as an earlier unacknowledged message may exist that still needs to be disseminated. Explicit cancel messages might have the ability to aid in this area, but such explorations are left as a future research.
If I have a very long thread of messages, I would like to be able to stop forwarding the very-old messages to all peers. A peer should be able to say "I only forward the messages which match a condition" (for example "not too old", or "not too far" for maps). This is currently not possible because the manifest needs to be signed by the sender. But maybe the sender is not connected and will not be connected anymore.
The "drop-only-by-the-sender" behaviour is typically a problem for microblogging (the log will grow without limit over time).
But there is another problem. We have (at least) n several bundles, one for the list of messages of peer 1, one for the list of messages of peer 2, …, and one for the list of messages of peer n. They are timestamped, but there is no global clock, so there is no way to guarantee causality.
For example, in a distributed chat room, an answer can be timestamped with a lower value than the question, which breaks causality.
I managed to produce the problem in practice with current MeshMS.
Take 3 devices, A, B and C.
If A clock time is t, then configure B to be t+k1 and C to be t-k2, with k1 and k2 any positive time amout (not too small for having time to write messages, for example 2 or 5 minutes).
For example:
Launch Batphone on all of them, connect to an AP, but stop servald.
After these steps, causality can be broken on B:
Here is the screenshot of my B device:
In my opinion, there is slight lack of separation between the store-and-forward service (Rhizome) and the service built on top of it (MeshMS, filesharing, maps…). It would be great if anyone could be able to build its own service on top of Rhizome (as anyone can create its own service on top of TCP), without modifying Rhizome code nor database, and benefit from the store-and-forward mechanism for any service they can imagine.
My goal is to target all of these problems.
My inspiration comes a lot from your ideas in the current version of Rhizome and from the concepts of GIT.
There can be some drawbacks I did not see, I count on you to highlight them.
The main idea is, instead of storing one linear log per peer, storing one global graph.
The easier way to explain it is to take an example, here is a graph of chat/microblogging messages:
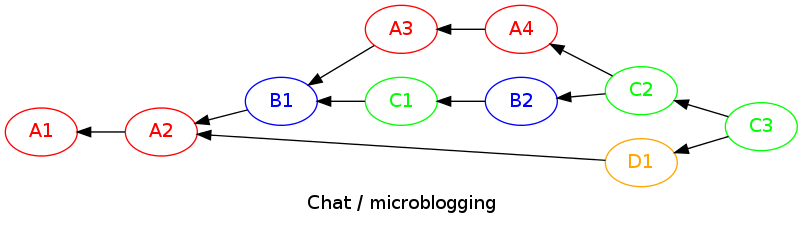
There are 4 users A, B, C and D. The relationships are set by the sender of a message: when they send, they check their local part of the global one, and set the "leafs" as parents of the new message.
In this way, the causality is known: if I already get these messages, then they are before the one I am sending. With transitivity, setting these parents nodes means "the message I am sending is after all the messages I already have".
Thus, we have a partial order. On the example, any client can know that B1 is after A2, or that C2 is after A4 and B2. But the order is not complete: the order of C1 and A3 are undeterminate for example, because there is no causality between them.
The client is also able to discard old data (drop payloads) but keep graph information:
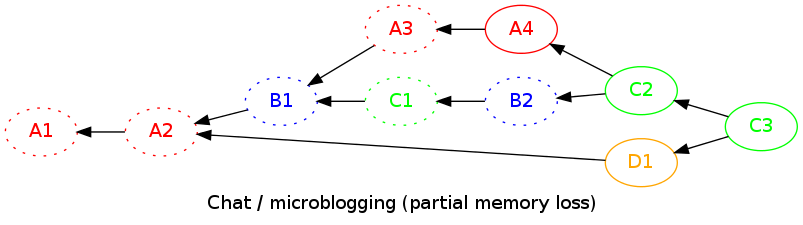
You can imagine removing a node without removing neither its parents or its son (it i weird for a chat service, but it is good for MeshMS, when we receive the ack of only one message "in the middle").
Note that this is only a local removal: the peer will not transfer these data anymore, but will not tell the others to delete them.
In this example, it removes only the payloads, but keep trace of the graph log.
The peer can also remove a part of the graph log (very useful for a microblogging service, we want to keep only recent data):
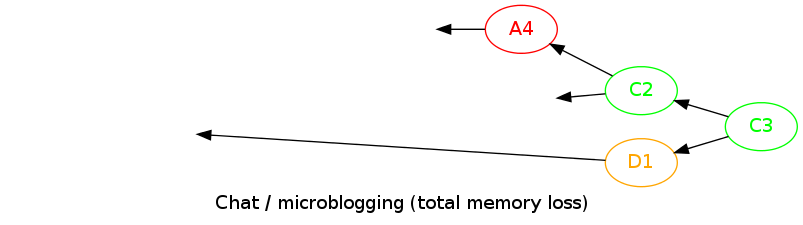
Note that the removal is only local too: some other nodes can choose to keep data longer (depending on their available memory for example).
These two mechanisms allow any peer to progressively forget about old data.
But for really deleting data, the sender still must change the node version, set a delete flag and sign. If they do that, then all peers are asked to delete the data.
Nobody can delete the data globally if they are not the owner.
I propose 3 types of objects (or tables if implemented in database):
They represent the graph (the local known part of the global graph).
Think of RNODE a bit as if it were GIT commit (git cat-file -p <commit>).
It contains:
RNID (equivalent of your current BID)version (incremented by 1 every time the owner changes something)service (service name, like meshms, chat, maps…)data_length (size of payload, -1 means deleted)data_hash (payload key, which is its hash)sign (signature of RNODE content + parents using the private key associated to RNID)The big difference wih GIT commit is that it is not identified by its hash, but rather by the RNID, a public-key associated to a private-key the creator of the RNODE own. Thus, contrary to GIT, it is possible to modify (only the owner can do that) the RNODE without changing its key (they must increment version in that case).
Same as your FILEBLOBS:
data_hash (payload key)data (blob)Junction table for n-n relationships between RNODEs (a RNODE can have n parents and m sons):
RNIDparent_RNIDNote that the parents of a RNODE must be taken into account for hashing/signing the RNODE: only the owner can set the parents.
You should have noticed there is no sender, recipient, date or name information: they concern the protocols on top of Rhizome:
Rhizome just stores-and-forwards graphs (meta+payload), it does not care what's in the payload.
All the services (even non-existant yet) can benefit from the Rhizome protocol without any need to hack it. They just implement their custom part in the Rhizome payload, exactly like HTTP protocol is written in TCP payload: TCP don't even know that it transports HTTP. The Rhizome protocol provides a service field for delivering to the right handler (a bit like TCP provides a port number).
Note that it is up to the protocols on top of Rhizome to set the parents relationships. For example, if a chat service supports multiple channels, we don't want to store causality between the messages in both channels: we want to keep them independant.
From the information stored in these objects (in database for example), we can produce a graph description on demand (we can also cache it).
This graph description contains:
There are a lot of ways to represent this graph description.
For example (but I don't want to enter too far in details), each node is identified in this graph description by (RNID, version), which takes 36 bytes (32+4).
If we always list parent nodes before their children, then we can describe the edges with only the list of parent node indices in the nodelist. These node indices can have a variable length using the same trick as UTF-8: thus, in practice it will always take 1 byte, but if exceptionally a node has more than 127 nodes, we can store it in 2 bytes (or more).
The list of parents is terminated by a 0-byte (so node indices must start at 1).
For describing this graph:
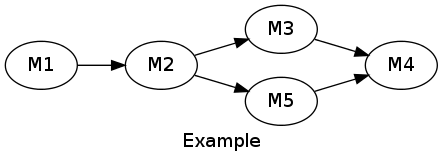
The result would be (the number between brackets is the implicit node index):
M1.RNID|M1.version|0 (1)M2.RNID|M2.version|1|0 (2)M3.RNID|M3.version|2|0 (3)M5.RNID|M5.version|2|0 (4)M4.RNID|M4.version|3|4|0 (5)Let's call this blob GRAPH_CONTENT, then graph description is: hash(GRAPH_CONTENT)|len(GRAPH_CONTENT)|GRAPH_CONTENT
Note that len(GRAPH_CONTENT) can also be stored as variable length.
As each {node + its edges} takes about 40bytes, a good estimation of the length of this blob is size(hash) + ~4 + ~40 * node_count.
We can send more than 20 nodes per MDP packet (1Kb) (if implemented over MDP).
For 2000 nodes, it takes 100 packets, which is still acceptable for single hop.
But the peers will exchange this graph description only when needed: each one store somewhere the hash(GRAPH_CONTENT) (the key of the graph description) for every SID peer it knows. Periodically, then exchange only this key.
If and only if the hashes are different, the new graph description is retrieved, and its key associated to the peer SID is updated, as well as the local known part of the global graph (union of nodes and max of versions).
Independently and periodically, the client asks for nodes it knows (in graph description) but for which it does not have the payloads (and that it has not discarded locally). Note that it is possible that the peer from which we received the graph description don't have these payload either: it can have discarded them locally.
The request of all differences can be a list of RNODEs, but it should be smarter like rnode1..rnode2+rnode3..rnode4 (in GIT notation). This is a kind of git fetch.
If this architecture is ok, then maybe we can avoid using sqlite3 database for that: we can store the data the same as GIT does, in files. But this is another discussion…